
This Explainer-series is aimed at describing the “many ways to the cloud”. It will help you to choose the best way of porting your research onto the cloud.
Running your research on public cloud infrastructure (AWS, Azure, GCP) has many benefits such as cost-efficiency, access to the latest technology, and high security standards (for more information please see our cloud-native Explainer). But getting started can often be a steep learning curve, especially since there is not one single way of tackling this issue.
In fact, there are many “ways to the cloud”, ranging from installing existing code on cloud-based virtual machines (lift-and-shift) to completely (re-)designing into cloud-native workflows. Choosing one, the other or a middle way depends on the situation. We tailor our approach for every project to efficiently set up a solution that produces outcomes quickly and is scalable to future challenges.
In this blog post we describe the adoption of the EMR Serverless service offered by AWS for reimplementing INSIDER, our tool for detecting foreign DNA integrations, in the cloud.
The research problem
Last year we published INSIDER, a tool for alignment-free detection of foreign DNA sequences. It can be applied to diverse areas such as monitoring the spread of anti-microbial resistance, watching out for side-effects in gene therapy or recognising novel biosecurity threats.
As a follow-up on this, the idea was to transform INSIDER into serverless INSIDER (sINSIDER), i.e. reimplementing the pipeline in the cloud. This has several advantages: the platform can handle more diverse workloads due to auto-scalability, enabling faster and more cost-effective processing of incoming requests. It also removes the need for a local cluster, making our open-source research more accessible to research teams without on-premises infrastructure. And finally, it opens new possibilities like making the application accessible to users beyond bioinformatics such as clinicians or wet-lab researchers via a user-friendly web interface.
The cloud architecture
Instead of a simple lift-and-shift procedure, we wanted to take advantage of the unique possibilities the cloud offers and restructure the INSIDER application to make use of these advantages.
INSIDER relies on Apache Spark, an engine that orchestrates distributed programs, i.e. programs that do not run on a single node but on a cluster of nodes (either local or in the cloud). We wanted to keep this integral part of the INSIDER pipeline and therefore decided in favour of the EMR Serverless service that AWS introduced recently in June 2022.
EMR Serverless is the new, serverless version of the managed EMR service and enables us to create transient clusters that are created whenever a job request arrives and are torn down once the job is finished. Since our workflow is sporadic and fluctuating (at times there will be many jobs, at other times there will be none), such a pay-as-you-go model suited our purpose.
Cloud architecture for sINSIDER
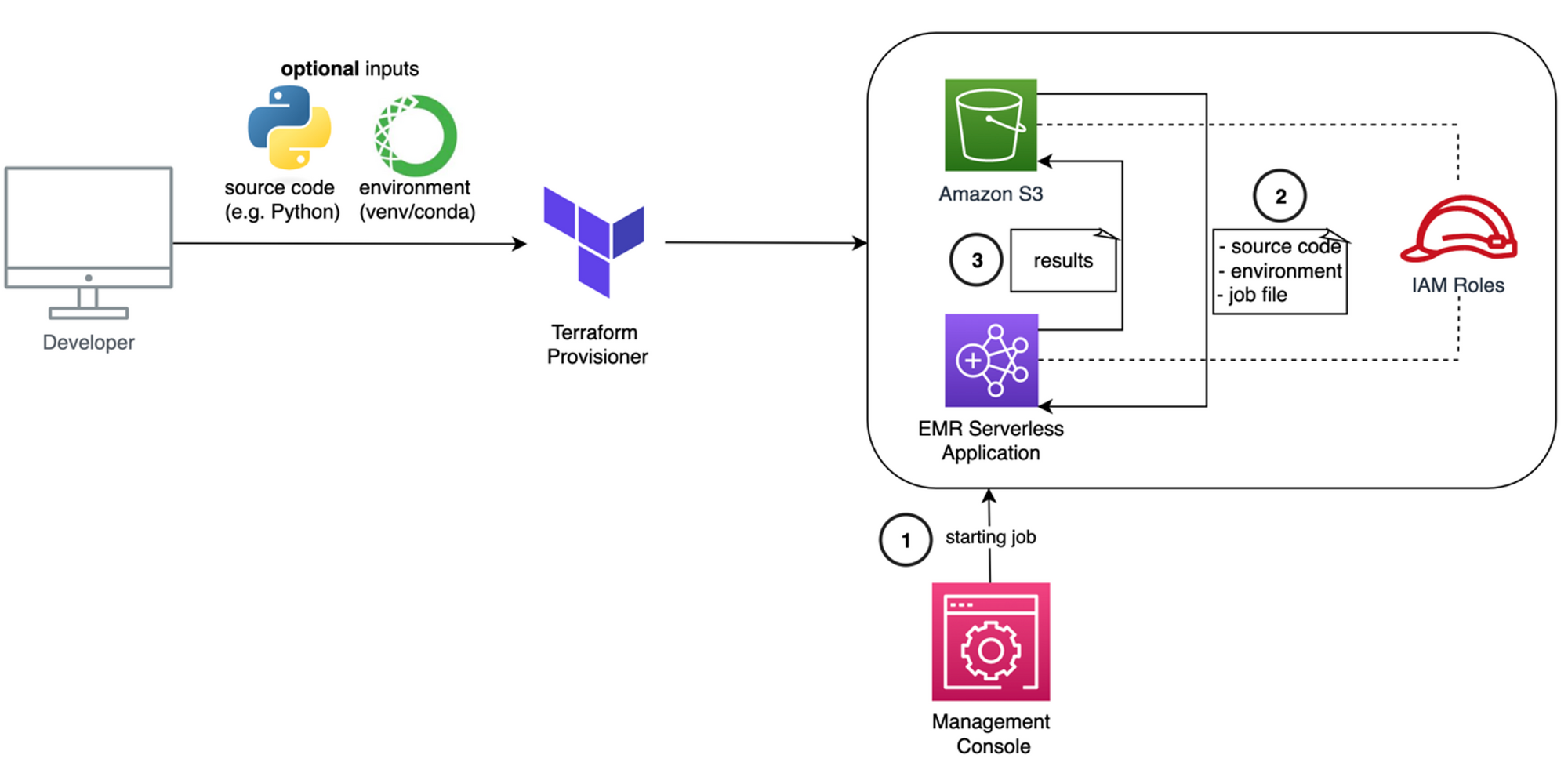
Reimplement INSIDER to work with EMR Serverless
To leverage the full potential of EMR Serverless, we made a lot of changes to the original INSIDER pipeline. For example, instead of writing and reading the data from disk between every step of the pipeline, we streamlined the code so that the data flows without interruption, allowing Spark to work its magic by optimising code execution under the hood and minimising the time our data spends in the transient EMR cluster, reducing cost and increasing speed.
When restructuring a whole code pipeline, it is to be expected that troubleshooting will have to be done. Things sometimes work a bit differently in the cloud compared to local execution, so that simple things such as file access and data manipulation have to be rethought. However, the reward comes with an efficient and modular application that plays out the cloud card very well.
Moving to infrastructure as code
Bioinformatics solutions are constantly evolving and thus the frequent updates to the pipeline or the webpage need to be staged and tested in the development environment before being pushed out to the production environment. Moreover, all the bioinformatics solutions we develop need to be reproducible for clients. To be able to easily reproduce the solution infrastructure in different environments, we wrote infrastructure as code using Terraform. The full architecture is implemented as code, so everything from the roles and permissions to the actual analytics code can be defined and rolled out by a single command
Since the EMR Serverless service used in our case was publicly released only one month prior to our work, there was no Terraform module available. So we created our own, made it publicly available in the Terraform Registry and added some extra functionality to it that you can see in the cloud architecture diagram above. With this service, everyone can get an EMR Serverless cluster up and running quickly without having to worry about issues such as IAM roles or bucket policies.
Our Terraform module combines convenience with flexibility, providing default values for most parameters but allowing a great deal of customisation. For instance, users may want to restrict the maximum capacity of computing resources their application can access in order to reduce costs: this can be easily configured using the maximum capacity parameters.
Other users may want to have some initial computing resources available around the clock, trading the $0 idle costs for a quicker start-up of the cluster: this can be configured as well using the initial capacity parameters. While this flexibility is available, it is still very easy to provision a “standard” EMR Serverless application by just providing the application name; all other parameters can fall back to default values. If you want to have a go with the Terraform module yourself, here you can find a tutorial on getting started with it and EMR Serverless in general.
Making bioinformatics accessible
The cloud implementation has another benefit – without reliance on the local server infrastructure, the application can be used by a variety of researchers outside of our group, especially where its functionality could have its biggest impact: in the clinic.
To foster adaption of our platform, we open-source our application and infrastructure code and make it available to other bioinformaticians, enabling them to use our modular implementation as a toolkit to use and expand on.
But besides programmatic access, we also aim to provide a webpage with a graphical user interface in order to enable clinicians and wet-lab researchers to use our bioinformatic tools. All the user needs to do is upload the DNA sequences to the cloud via the website to quickly gain insights, including identification of integration events.
The goal is to enable both researchers and clinicians to watch out for events such as antimicrobial resistance in hospitals or viral integration in gene therapy trials and will therefore improve both the present situation in hospitals as well as the future of new therapeutics.